

About KDB
For installation instructions for a local copy of KDB and command line usage, click here.
Motivation
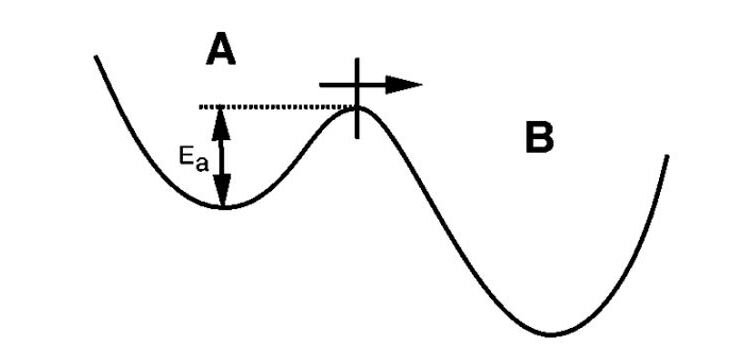
A major challenge of modelling materials is capturing the timescales over which chemical reactions take place. The most natural way of doing this is using molecular dynamics (MD), where Newton’s equations of motion are numerically integrated. However MD simulations are only accessible over time scales up to nanoseconds, while most experimental chemical reaction occur at much longer time scales. One strategy for overcoming this timescale gap is using adaptive kinetic monte carlo (AKMC). AKMC simulates how atoms move over time by utilizing harmonic transition state theory (which essentially assumes that Arrhenious rates can be used to calculate chemical reaction times). In order to predict the reaction which will take place with AKMC out of a reactant state, researchers need to find all the low energy probable processes that could take place, and the saddle points or reaction barriers for these processes. Once the barriers are obtained, predictions can be made for the rates of a reaction and the probability that different processes will take place. Based on these probabilities, a random product state is selected and it is moved within the simulation, and the process is repeated by finding all relevant reaction barriers again.
The most time consuming part of AKMC simulations is finding all of the relevant reaction barriers (or connected saddle points). Currently, researchers are looking into the most efficient way to find this complete set of saddle points for a given system. One way to speed up the search for saddle points is to use previously found saddle points from either the same system or a similar system. In this project, we plan to first generate a database of saddle points for various chemical reactions that could be used to speed up AKMC simulations. Then, we plan to edit related software so that it utilizes the database of saddle points.
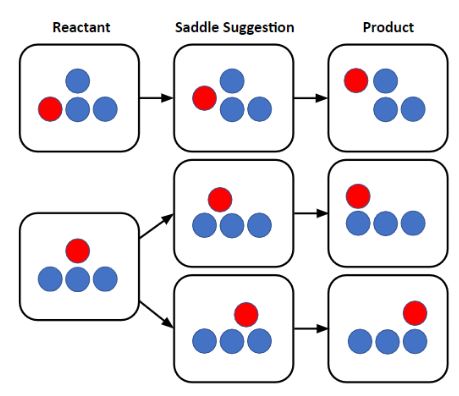
The Kinetic Database (KDB)
We have collected thousands of transition state calculations performed in the past by our group, and we plan to collect transition state geometries for catalysis and battery materials from the above literature. The collected information is been indexed and stored in the global database that is freely accessible on this website for use (see below on how to access). The database is created by inserting the minimum energy pathway from the transition state calculations (using reactant, saddle and the product configurations). The user is encouraged to read our paper that describes in detail about the insert and query process from the database, but to describe it briefly, we focus on finding a group of atoms that are involved in the process simulated by the transition state calculation and store the positions of those atoms in the database[1]. When a query is made to the database by providing a structure file (we call it queried reactant), the code uses a neighbor list depth first based matching process to find relevant processes associated with the queried reactant. We have also recently implemented a graph-based querying method using the VF2++ algorithm[2] (we call it USE_GRAPH), and we are comparing our original query method with graph method implementation to test the accuracy and efficiency of the database query.
How to use KDB
There are 2 "modes" of using KDB: global and local. Inserts and queries from KDB require at least 1 structure file (VASP, XYZ, or CON)
Global (aka Remote) Database
The global database is maintained on our server and is comprised of kinetic processes inserted by users around the world. There are 2 ways to access the global database:
Website
To query:
- User can query from the website without registering on the server by going back to the main page and submitting a query by drag-drop or selecting a structure file.
- User can also query from the website by logging on to our server from the main page, then clicking on the "option" button on top right and selecting "KDB Access".
To insert:
- Users with account on the server can contribute to the database by inserting processes into the database. To insert into the database, log on to our server from the main page, then click on the "option" button on top right and select "KDB Access". Then, use the "Insert" option by uploading the reactant, saddle and product files. Finally, click the "Insert" button to submit them to the global database.
- To create a new account, visit this page.
Command Line
To insert a process/query from the global database, you should have a local copy of the KDB code. See Instructions to install a local copy and use the command line.
Local Database
The local KDB is a SQLite database file on the user's local machine (by default, named kdb.db). The user must have a local copy of the KDB code installed in order to use this feature (see Instructions for installation). The database file is created by the code when the first insert is performed.
Command Line
After a successful installation, follow instructions here to use the command line.
Using local kdb with EON
EON is a client-server architecture platform developed by the Henkelman group that allows users to run AKMC, geometry optimization, global optimization, and transition state searches using different potentials and methodologies. EON has capabilities to use a local KDB to accelerate transition state searches for AKMC, dimer and NEB. User must have a local copy of the KDB code installed (see Instructions) and proper flags turned on in the config.ini file for running EON to use the KDB functionalities.
Current Limitations
In order for the inserts and queries to work properly, the process that is being inserted (to local or remote) must meet the follownig requirements:
- The cell basis vectors must remain unchanged through the process (reactant → saddle → product)
- There must be no atoms that move more than half the length along any cell basis vector from reactant → saddle, saddle → product, and reactant → product.
- If an atom is involved in the process (as either a mobile atom or a neighbor), its periodic image must not be also involved in the process.
- Periodic boundary conditions (PBC) is assumed in all 3 directions.
References
- R. Terrell, M. Welborn, S. T. Chill, and G. Henkelman, Database of atomistic reaction mechanisms with application to kinetic Monte Carlo, J. Chem. Phys. 137, 014105 (2012). DOI
- V. Carletti, P. Foggia, A. Saggese, and M. Vento, VF2++ — An Improved Subgraph Isomorphism Algorithm, Disret. Appl. Math. 242, 69-81 (2018)